A 面与 B 面(英语:A-side 和 B-side)是流行音乐业界术语,于 1950 年代开始常用,原本指出版的 7 英寸黑胶唱片(必须是单曲)的两面。现在 A 面和 B 面通常用来辨别歌曲的重要度——放在 A 面的歌曲为主打歌,歌手会期望这些歌经常在电台等传媒渠道曝光;放在 B 面的歌曲则属于次要或附加歌目。
前奏
前些日子,其实就是咱考完教师证(10.31)的第二天,便要前往出差。
晚间也成功地错过了万圣节。但想来这种现充的节日,也本就与我无缘。故也无从惋惜。
尽管是流水账,但勉强作为日记记录下来,以作为引入正题的前言。
A 面
这是我一个朋友的故事。只是为了方便叙述,我决定使用第一人称。

对了,文中引用的中二语录大部分出自于「我的青春恋爱物语果然有问题」中人称「大老师」的比企谷八幡之口,尽管可能真假参半,但不必与我的朋友的形象建立映射。
演奏者——出场人物
我:我的朋友,家里蹲死宅
LM: 我朋友的朋友
但我的朋友很少,因此很难确定朋友的定义。而我的朋友是否被朋友的朋友定义为朋友,我也无从知晓。 后续的事态发展,也让我的朋友更加怀疑起来。
序曲——旅程
2020.11.01
与同行的小伙伴 LM 约定好早间地铁站汇合,但其同样有睡懒觉的习惯,且此后发现闹钟定成了下午……(仿佛看到某个过去的自己)

于是改签了后续的高铁,座位也就此错开。
仅需一个多小时的高铁,便抵达目的地,L 老师与她的爱人也是 L 老师来接我们。(与此同时,我正在另一个 L 老师的课堂上摸鱼校验这些字。)
顺带一提,因为此次所见之人 L/Y/Z 姓众多,我愿称之为 LYZ 三方会谈。
主要活动便是,吃饭,围观,吃饭,围观,吃饭,围观……(偶尔干点体力活)
所谓的和人好好应对的行为,不过就是欺骗自己,欺骗对方,对方知道自己被骗,自己也被对方所骗,这样的连锁循环而已。说到底也不过是虚伪、猜疑和欺瞒而已。
遵循惯例,吃饭时自动开启自闭模式,尽管其他时刻也没有关闭的迹象。所以全程只能拜托 LM 同学接话。
此外也很害怕在饭点时,被提到吃素而引人注目受特别关照。
 一个人出差太简单了 带上这个吧
一个人出差太简单了 带上这个吧
略去无关紧要的琐事,简而言之,因为出差事项无聊(也许只是借口),开始探寻同行小伙伴社交账号的活动。
交响——探寻
因为鄙人各平台均基本使用同一个 ID,且基本没有什么重名,所以基本属于裸奔状态。相信大家也能在侧边栏轻而易举地发现我的一众账号。
而 LM 同学则声称各平台均使用了不同 ID,导致我无从下手。尝试使用相同 ID 在各平台检索,得到的似是而非的结果也被一一否定。



我也坚信,社交账号是在网络中构筑人物立体形象的一个个关键点。人与人本来就是互相联系的,无论是死宅也好,现充也罢,没有人是一座孤岛。
区别只是现充的联系多半存在于现实,而死宅的联系则多位于虚拟的网络空间罢了。
因为有些不服输,使用了特殊手段
SGK加谷歌/百度检索搜寻到了知乎账号,但也仅限于此。并从源头处获得了表情包。⬇️

至于微博账号,苦觅不得,决定放弃。
最后也许是由于太过可怜,陆续获得了网易云账号与一些关于豆瓣账号的提示信息。
- 豆瓣线索 1: 头像下半部分灰色调
- 豆瓣线索 2: 头像中有游戏手柄
- 豆瓣线索 3: 快乐 memers 小组
协奏——计划
终于进入正题。
原本无头无尾无异于大海捞针,而现既然有了若此多的线索,那么便可以尝试寻找一下。
因为确实显得有如网络跟踪狂一般,于是向本人确认了几次,大致得到了默认,所以将行动放心大胆地继续了下去。
A 大调 - 人工筛选
2020.11.09
因为想着暴力搜索或许是最简单的方式,于是我决定先启用 A 方案——人工检索(即手动翻页查看用户头像)。
在我进行检索之日,快乐 memers 小组共有 11534 位成员,豆瓣小组成员每页展示 35 人,共 330 页。 但很遗憾在翻完了 330 页的小组成员,也许是过于草率,并未能找到类似的头像。
此时,我也成功意识到,「人类是有极限的。」
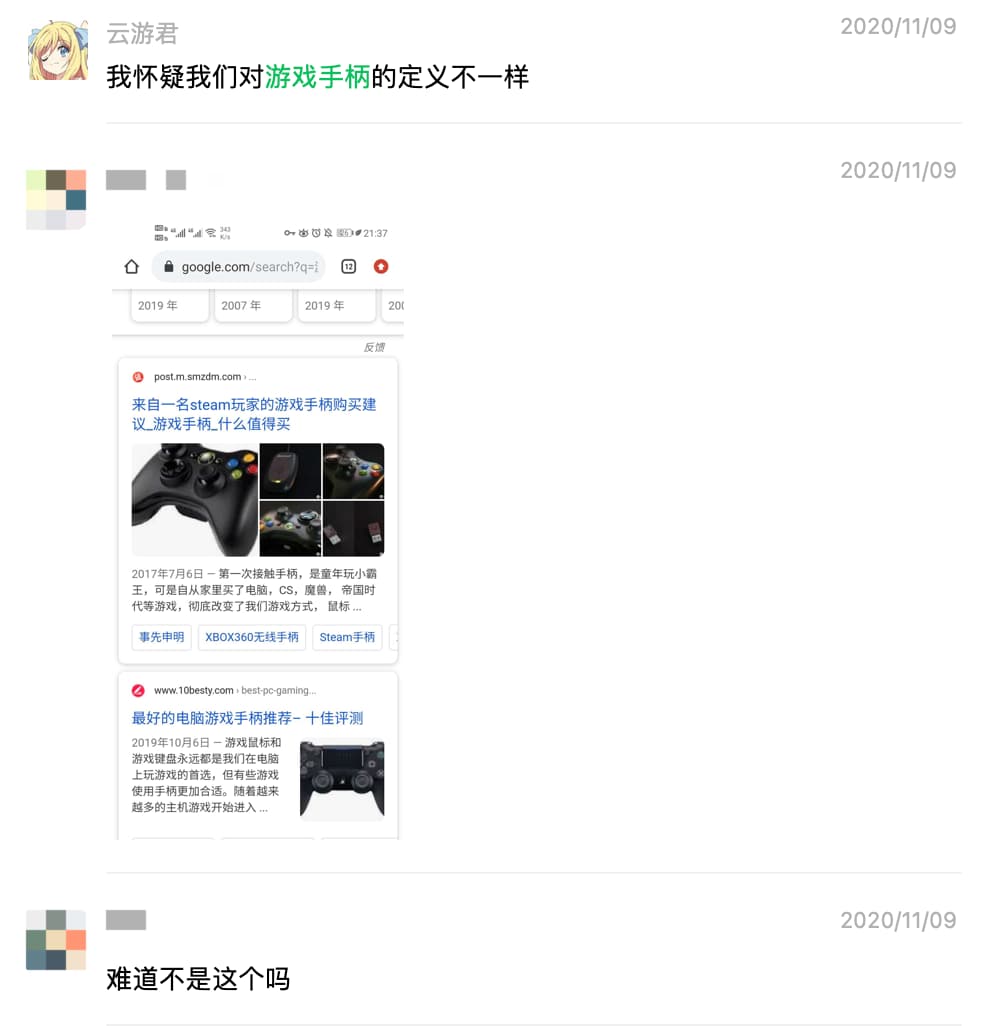
当然也进一步可以确定是类似上图的游戏手柄 🎮。
B 大调 - 目标检测
于是我决定启用 B 方案。
爬取下小组中所有成员的头像及对应信息,跑一个目标检测的模型检测图像中是否存在游戏手柄,以及可以计算图像下半部分的饱和度与亮度均值,排除掉亮色的图片(这一部分最后鸽了)。
新建私有仓库 find-lm(404 警告),开整。
爬取豆瓣
豆瓣的反爬规则是出了名的。而其官方 API 也在前几年全部神隐,第三方的一些代理或文档如 douban-api-docs 也逐渐消亡殆尽。因此只得自行去 HTML 页面爬取。
首先豆瓣小组成员页面的链接格式是 https://www.douban.com/group/702484/members?start=0。可以通过设置 start 参数进行查询,而每页最多显示 35 位成员。
所以我决定先用 cheerio 通过 class 选择器去获取成员列表,并记录几个最重要的信息,如 UID、姓名、城市。当然最重要的是头像啦,但是成员列表中的头像其实是缩略图,并不清晰。为了此后的处理,一定是获取大图更为合适。
一般情况下,用户的头像其实和之前爬出来的 UID 有关。
/**
* 根据 UID 获取大头像
* @param {*} uid 用户ID
*/
function getAvatarUrlByUid(uid) {
return `https://img2.doubanio.com/icon/ul${uid}.jpg`
}但是测试时,发现又并非如此。此前获取 UID 其实是通过用户的个人链接进行截取所得。
/**
* 根据链接获取 UID
* @param {string} link 链接
*/
function getUidByLink(link) {
const url = new URL(link)
const uid = url.pathname.split('/')[2]
return uid
}但是,有些用户其实会自定义用户名,比如我就喜欢自定义域名,我的豆瓣主页便是 https://www.douban.com/people/yunyoujun/,最后的 ID 为 yunyoujun 而非一般的数字 ID,而我无法确定 LM 同学是否也有这个习惯,所以最好也做一下兼容处理。
一般数字 ID 的用户头像原图可以通过简单拼接链接获取,而自定义域名的用户还需要再访问一下用户页面进行获取。
/**
* 根据用户 url 获取高清的头像
* @param {string} url
*/
async function getAvatarByLink(url) {
const html = await axios.get(url).then((res) => {
return res.data
})
const $ = cheerio.load(html)
const avatarUrl = $('.basic-info img').attr('src')
return avatarUrl
}OK,万事俱备。整一个循环来获取用户信息,并下载头像吧!
爬取个人用户信息的时候,还需要提供一下用户的 Cookie,可以在登录后的豆瓣页面用控制台工具找到。
(对了,因为防止被关小黑屋,一定要慢一点爬……)
至于我为什么知道?如下图所示。
403 Forbidden | nginx

/**
* 睡觉!
* @param {*} ms
*/
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms))
}
/**
* 获取所有成员
*/
async function getAllMembers(groupId) {
const totalPages = 330
let memberList = []
for (let i = 0; i < totalPages; i++) {
// 休息一下
await sleep(5000)
console.warn('休息五秒,防止太快,被关小黑屋!')
console.info(`爬取第 ${i + 1} 页...`)
const list = await getMemberListByPage(groupId, i)
memberList = memberList.concat(list)
}
return memberList
}Done in 2826.76s.
用户信息的 JSON 数据 683KB,头像的图片一共为 151.7MB。(搜完咱会删掉的~)
想来 LM 同学的头像应当已经位于其中。
于是可以进行后续的过滤工作。
准备训练数据
本来想使用 Bing Image Search API 来获取做训练的图片。
突然发现微软竟然还支持 GitHub 登录了。
但是咱没有信用卡……,但是天无绝人之路,搜到了面向学生的 Azure,似乎使用学校邮箱,便可无需信用卡。
但是发现使用学校邮箱也还是不行。
还是老老实实地自己爬吧!
于是,诞生了 baidu-image-spider。
# 使用方式
bis -k '游戏手柄' -tp 100爬取 100 页,每页默认数量为 30。(其实最后只爬下来 1628 张,不过先将就用了。而且其实越往后很多图片不是很相关,可以手动删除。)
你们也可以用 bis -k 美少女 的方式来爬取一些美少女图片。
因为中途爬取豆瓣用户、百度图片的代码放在了不同仓库,但是其中有一些可以复用的地方(比如 sleep,检查文件目录是否存在不存在则新建,下载图片之类的)。 索性就再抽取一个工具类的库 utils,以供日后需要的时候可以直接安装使用。
yarn add @yunyoujun/utilsYOLOv5
目前比较知名的目标检测的技术方案是 Yolo,而其已经到了 v5 版本,即 yolov5。
仓库 README 中提供了自行训练数据的教程。
那么我们不妨按照步骤来。
安装环境
git clone https://github.com/ultralytics/yolov5 # clone repo
cd yolov5
pip install -r requirements.txt # install dependenciesCreate dataset.yaml
yolov5/data/gamepad.yaml
我只需要检测一个 gamepad(游戏手柄)的类。
# download command/URL (optional)
# download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /Users/yunyou/github/lab/find-lm/tmp/images/gamepad/
val: /Users/yunyou/github/lab/find-lm/tmp/images/gamepad/
# number of classes
nc: 1
# class names
names: [gamepad]Create Labels
而 Create Labels 部分,我也没啥精力去挨个标记游戏手柄的范围,就假装范围内的都是吧。(这也导致了后续的……)
需要再写一个脚本去生成 *.txt。
要求放置的格式是:
coco/images/train2017/000000109622.jpg # image
coco/labels/train2017/000000109622.txt # labelconst fs = require('node:fs')
const path = require('node:path')
const yyj = require('@yunyoujun/utils')
const imagesPath = 'tmp/images/gamepad'
yyj.fs.checkFolderExists('tmp/labels/gamepad')
const files = fs.readdirSync(imagesPath)
files.forEach((file) => {
const filename = path.basename(file, '.jpg')
const uri = `tmp/labels/gamepad/${filename}.txt`
const label = '0 0.5 0.5 0.98 0.98'
fs.writeFileSync(uri, label)
})Train Data
因为 --weights yolov5s.pt (recommended),所以就先用 YOLOv5s 小模型试试。
python train.py --img 640 --batch 16 --epochs 5 --data gamepad.yaml --weights yolov5s.pt跑的时候发现有些图片可能不是 jpg 格式或者太大或者是 sRGB 颜色描述文件读取不了,需要删掉。
File "/Users/yunyou/github/lab/yolov5/utils/datasets.py", line 628, in load_mosaic
img, _, (h, w) = load_image(self, index)
File "/Users/yunyou/github/lab/yolov5/utils/datasets.py", line 589, in load_image
assert img is not None, 'Image Not Found ' + path
AssertionError: Image Not Found /Users/yunyou/github/lab/find-lm/tmp/images/gamepad/1215.jpg不过没有找到其他合适的快速转换颜色描述文件的方式,所以跑到有问题的图片就删掉,或者自行截图,截图默认存的是 png,再放到 Squoosh 压缩下载得到的 jpg。
macOS 下有个
sips的终端命令可以转换图片格式。 Linux 下则有 ImageMagick。 不过都没有发现可以调整颜色描述文件的方式。
如果有更好的方案可以推荐给我。
跑了三四个小时,训练完毕。
Visualize
注册了个 wandb 账号,查看训练过程。(虽然好像没什么用)
Detect
# python detect.py --source data/images --weights runs/train/exp6/weights/last.pt --conf 0.4
python detect.py --source /Users/yunyou/github/lab/find-lm/tmp/images/avatars --weights runs/train/exp6/weights/best.pt --conf 0.88但我只希望展示有检测到 游戏手柄 的图片,所以需要对 detect.py 进行些许改造。
检测到物体时,会使用 plot_one_box 绘制边框,那么我们找到这段逻辑,如果没有绘制,就不存储图片。
定义一个临时变量 export_img = False,然后判断:
...
if save_img or view_img: # Add bbox to image
label = '%s %.2f' % (names[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
if conf:
export_img = True
else:
export_img = False
...
if save_img:
if dataset.mode == 'images':
if export_img:
cv2.imwrite(save_path, im0)
...因为训练集又混乱又少(自己也压根没有标),所以得到一堆并不相关的图片,可爱的玉子也是 Gamepad 了。
跑了 4884.034s,过了遍最后结果(大概几十张图片),果然没有发现什么像游戏手柄的东西。

加之后又从本人处得到了手柄色彩本就与背景十分接近,很难检测到的信息,所以不得不更换方案。
B 方案宣告失败。
所以我之前都在干什么???
B 方案的确折腾了我很久的时间,失败后自然有些失望。但在失望之前,我有幸又得到了一些新的信息。
C 大调 - 过滤城市
2020.12.02
此前,因为 LM 同学的其他社交账号也基本没有填写什么性别/城市信息,所以从一开始便没有打算从此入手。
偶尔汇报 B 方案的进展,并阐述了一些遇到的困难后,LM 同学却提到为什么不先过滤一遍数据呢,比如筛选城市,方察觉好像的确存在些许可能。(以及既然本人已经这么说了,可能性就更大了。)
那么要么是我们目前所在的北京,要么便是其家乡湖南某个城市 LD。(好在有先见之明的我,此前也爬取了用户的城市信息。)
接下来只要写个简单的脚本,拿到包含对应城市的成员列表。
/**
* 根据城市获取相关成员
* @param {*} city
*/
function getMembersByCity(city) {
const results = []
members.forEach((member) => {
if (city.includes(member.city))
results.push(member)
})
return results
}因为头像之前已经拿到过了,所以直接去拷贝一下就好。
/**
* 拷贝文件
* @param {*} src
* @param {*} dist
*/
function copyFile(src, dist) {
fs.writeFileSync(dist, fs.readFileSync(src))
}
const beijingMembers = getMembersByCity(['(北京)'])
checkFolderExists('tmp/images/city/beijing/')
beijingMembers.forEach((member) => {
const filename = `${member.uid}-${member.name}.jpg`
try {
copyFile(
`tmp/images/avatars/${filename}`,
`tmp/images/city/beijing/${filename}`,
)
}
catch (err) {
console.log(err.message)
}
})总共才七百来张,手动过一遍好像也不麻烦。

打开 finder 画廊模式,啪,很快啊,就找到了。
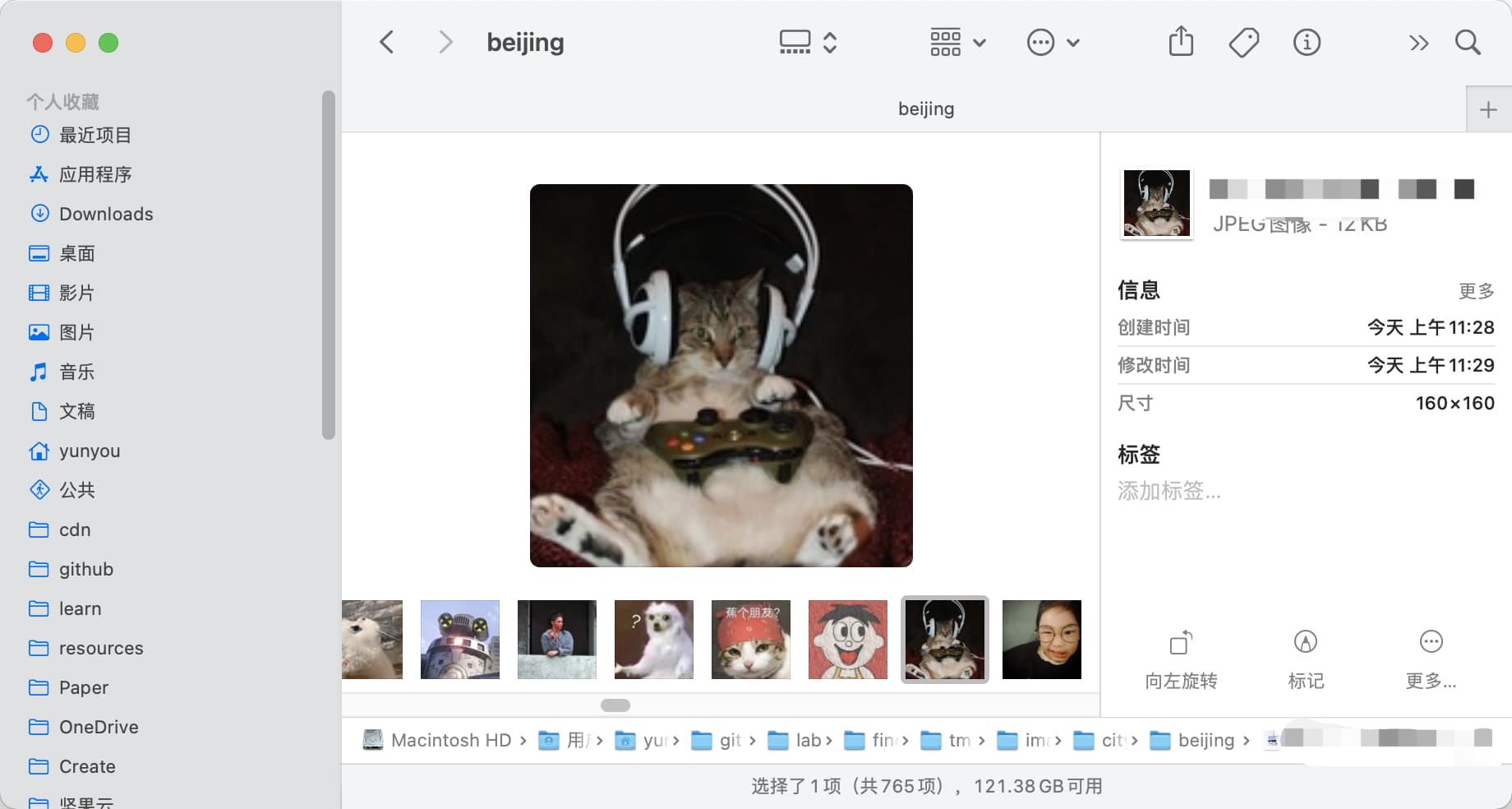
加之名称是此前提过的一个乐队名字的中文含义,因此也较为确信。
在点开个人主页时,则基本可以确定。因为早在半月前便留下了这样一条广播,我却因为走了许多弯路才抵达。
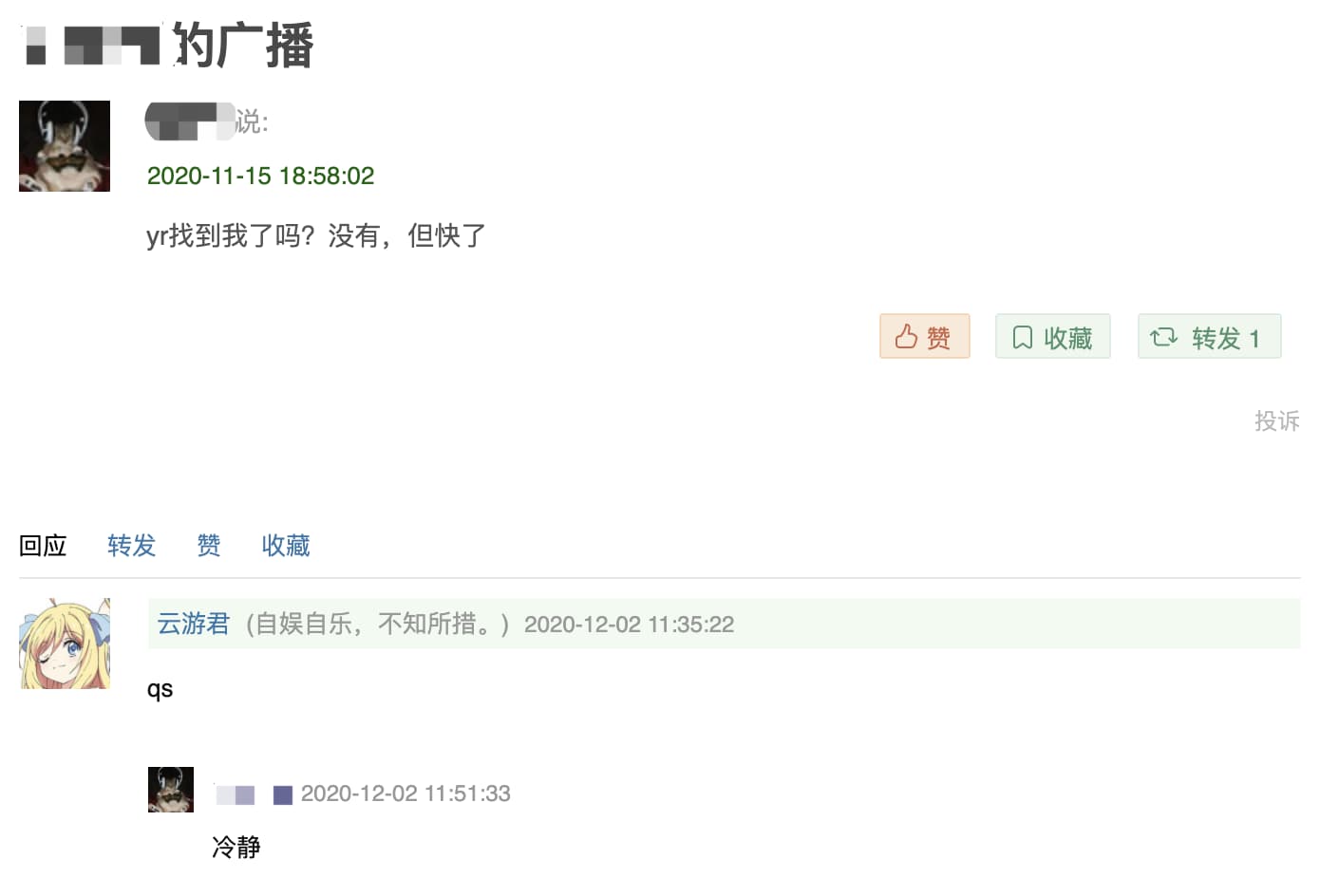
不要回答!不要回答!不要回答!
因为 LM 同学本人希望能与外界达到一种隔离的忘我状态,于是拉黑了历经千辛万苦找到她并关注的我,并已经改名删掉该动态了。
所以也请大家引以为鉴。
尾声
A 面的故事到此就结束了。
唱片的 A 面放完后,我也无法确保 B 面是否值得一听。
A-Side 和 B-Side 最初是指 7 英寸黑胶唱片的两面,唱片业从 1950 年代开始使用这种介质录制单曲。A-Side 和 B-Side 逐渐被用于形容录制在碟片两面的两种不同类型的歌,A-Side 通常录制的是我们所说的主打歌(那些被用来打榜或者期望在电台节目里热播的曲目),B-Side(或称 flipside)是指的第二类歌,这些歌通常不会出现在乐队的 LP(Long playing record album)中。
B 面
B 面
我知道倘若不迈出某一步,故事便不会开始与结束。
就像不把唱片放到唱片机上,便不会放出音乐,不把唱片翻转,就不会听到 B 面这样简单的道理。
那么回到 A 面的最初,我为何要寻找 LM 同学的豆瓣账号。
这里是尚未写完的 B 面,我的朋友因为事态的发展正处于低沉时期,所以还未能将之写完。
也许在某一天,无论好坏,这个故事的结局都会在此浮现。
我已经受够了自作多情的期待,最后又为此失望。因此我从最初就不抱期望,以后不会,直到最后也绝不期待。
To Be Continued.


